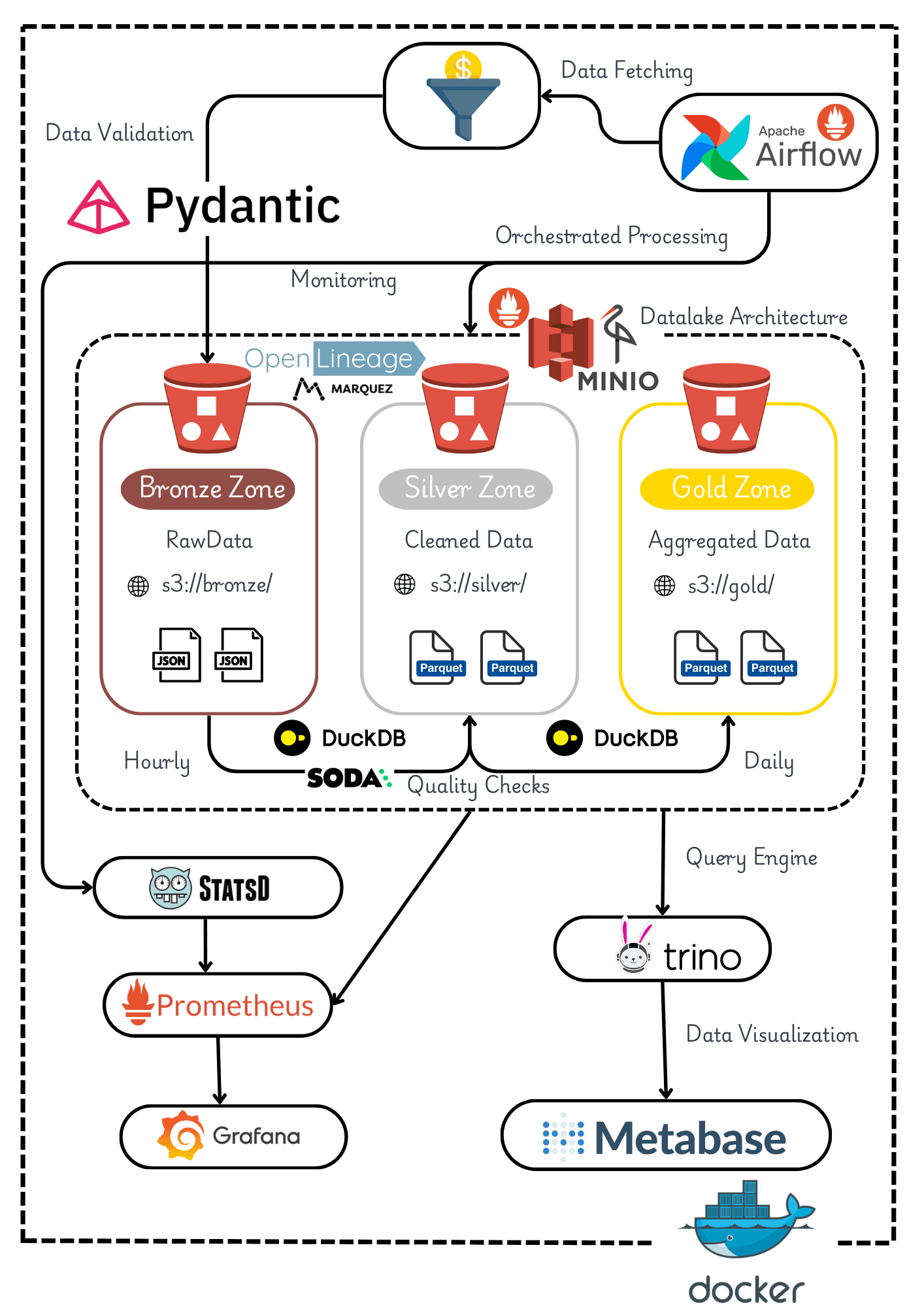
About this project
This project demonstrates a batch data pipeline following the Medallion Architecture (Bronze → Silver → Gold). It showcases how to ingest, clean, validate, aggregate, and visualize sales data using modern data engineering tools, all containerized with Docker for easy deployment.
🔎 Technologies Used:
Orchestration: Apache Airflow
Data Processing: DuckDB
Data Lake Format: Delta Lake
Object Storage: MinIO (S3-compatible)
Query Engine: Trino
Visualization: Metabase
Data Quality: Soda Core
Lineage: OpenLineage + Marquez
Observability: Prometheus + Grafana
Data Flow:
Data Generator simulates realistic sales transactions with intentional data quality issues (~20% dirty data)
Bronze Layer ingests raw JSON data to MinIO without validation
Silver Layer cleans, validates, and deduplicates data into Delta Lake tables
Quality Checks validates Silver data using Soda Core with 15+ checks
Gold Layer creates business aggregations (daily sales, product performance, customer segments)
Trino provides SQL interface for querying Delta Lake tables
Metabase visualizes business metrics through interactive dashboards
Marquez tracks data lineage across the entire pipeline
Grafana monitors pipeline health and performance metrics
🏆 Key Features
✅ Medallion Architecture
Bronze → Silver → Gold layers
Progressive data quality improvement
Clear separation of concerns
✅ Data Quality First
15+ Soda Core validation rules
Automatic dirty data generation for testing
Quality metrics in Grafana
✅ ACID Transactions
Delta Lake for Silver/Gold layers
Time travel support
Schema evolution
✅ Idempotent Operations
Safe to re-run any task
Deduplication in Silver layer
Upsert operations in Gold layer
✅ Parallel Processing
Gold aggregations run concurrently
ThreadPoolExecutor with 3 workers
✅ Full Observability
Custom Prometheus metrics
Grafana dashboards
Data lineage with Marquez
OpenLineage integration
✅ Best Practices
Error handling & retries
Comprehensive logging
Health checks for services
Docker containerization
Stack:
Apache AirflowDuckDBDelta LakeTrinoPrometheus