Reddit ETL Pipeline in Docker
Reddit Data Engineering ETL Pipeline: Spark, Airflow, MinIO in Docker Medallion Architecture
0.0
0 reviews•
Apache Spark·
Apache Airflow·
MinIO·
Python·
SQL
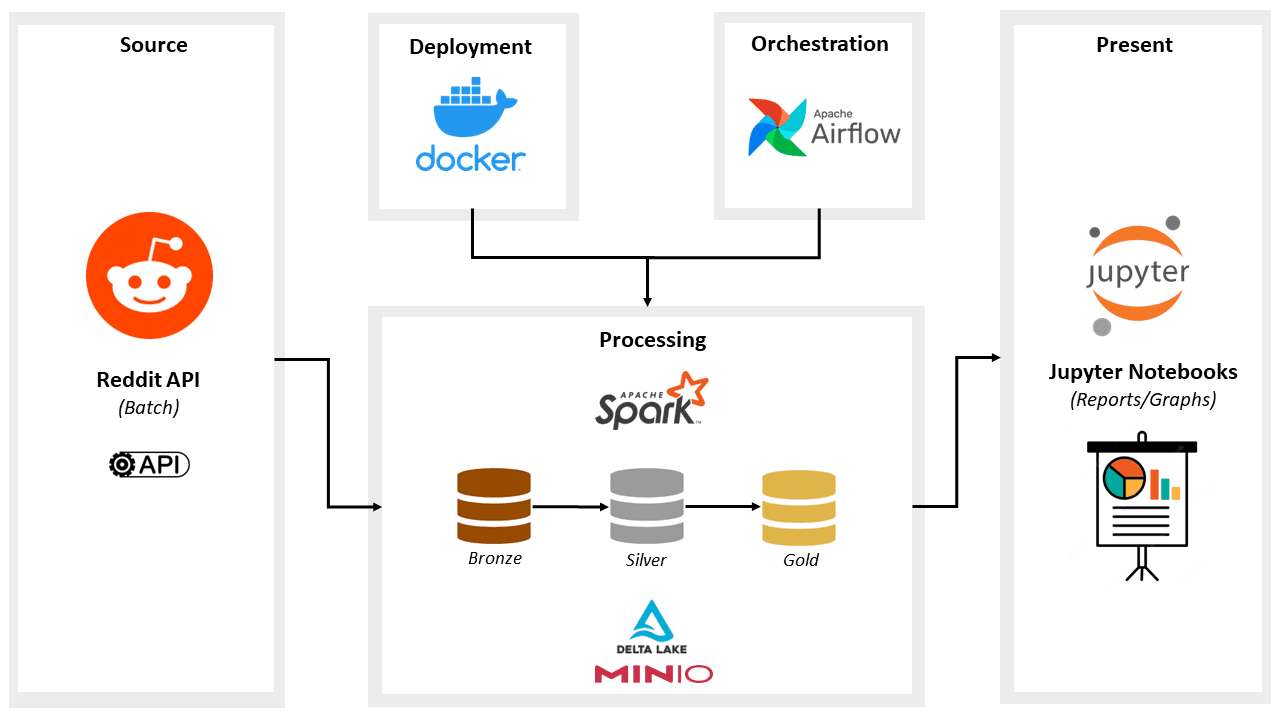
This project builds a full ETL (Extract–Transform–Load) pipeline that ingests data from Reddit (via Reddit API), transforms it using Apache Spark, and stores it in a MinIO-backed DataLake. The pipelin...
About this project
This project builds a full ETL (Extract–Transform–Load) pipeline that ingests data from Reddit (via Reddit API), transforms it using Apache Spark, and stores it in a MinIO-backed DataLake. The pipeline is orchestrated using Apache Airflow and packaged via Docker for easy deployment. It implements a layered “medallion” architecture (Landing → Bronze → Silver → Gold) to ensure clean, structured, and analysis-ready data. With this setup, you can run automated data ingestion and transformation, and then use the resulting dataset for analytics, dashboards, or further data-engineering experiments.
Stack:
Apache SparkApache AirflowMinIO